Abstract
We’re a team of three cryptography research engineers at PSE, and we’d like to propose/discuss an idea of integrating a private recommender system based on Federated Submodel Learning (FSL) into DevconPassport App.
TL;DR: FSL allows clients to locally train a submodel on their resource-constraint devices, and later a central server can securely aggregate the submodel updates uploaded by each client to construct a global model. From here, clients can fetch the global model to run inference on their input as conventional machine learning (ML). (We can additionally implement private inference, but that’s out of scope of this post)
Utilizing this protocol, Devcon participants can privately & collectively & build a recommender system that suggests talks or side events to go, based on the user inputs inside the DevconPassport app, without the central server even learning about them.
The purpose of posting this is mostly to discuss with DevconPassport develoment team so that we know finer application requirements and assess the technical feasibility better. But of course, weappreciate any comments or suggestions from anyone in the community.
Motivation and Rationale
Undeniably, recommender systems are becoming more and more inevitable component of our life. However, it comes with the cost of giving away your user data to a company. People are “fine” with it now, because the utility of the algorithm wins over privacy. We want to introduce a way to kill this tradeoff at Devcon. It will be a great opportunity to showcase a recommender system without giving up user privacy, given that Devcon attendees are one of the most privacy-conscious people. It will also offload the responsibility of collecting & securely managing user data from the Devcon team.
On top of that, we want to show that FSL opens up a whole new scene in AI business model, where smaller entities/individuals can collectively and privately train a model in a positive-sum way. The more participate in the private training, the more security guarantees & better prediction accuracy they get. I believe that this business model is going to be harmonious with dapps/web3 space.
Recommender Overview
Right now, users can submit following user profiles in DevconPassport app:
- job position
- tracks (categorization of talks)
- tags (topics you’re interested in)
There’s also a feature in the app that you can like speakers. This can be one of the features of the model.
Adding on to these existing features, it’d be fairly easy to implement a feature to rate/like talks that users have been to in real-time. Then, we can build a full/global model to predict how much each participant will rate/like a certain talk such as below:
| User ID | Job title | Tracks | Tag | Talk 1 | … | Talk 100 |
|---|---|---|---|---|---|---|
| User 1 | Developer | Scaling | ZKP | 2 | … | 4 |
| User 2 | Researcher | Cypherpunk | zkVM | 3 | … | ? |
Using this model, we can suggest talks/side events to go.
System Architecture
Components
-
Client-side: User’s mobile devices
- DevconPassport
- User will interact with the DevconPassport app
- Client will fetch the latest global model for inference
- DevconPassport global page will be updated internally to apply the results of inference with the global model
- Submodel learning
- Each user locally trains a submodel on their device using their data (e.g., user profile, rating, liked talks, etc)
- The trained submodel will be uploaded to the server
- DevconPassport
-
Server-side
- Collects submodel updates
- Securely aggregate the updates
- Distributes the updated global model
-
Some kind of UI to show positive-sumness of this collective & private training
- Good example: https://ceremony.ethereum.org/
- Maybe we want to add some graphics to make it more intuitive
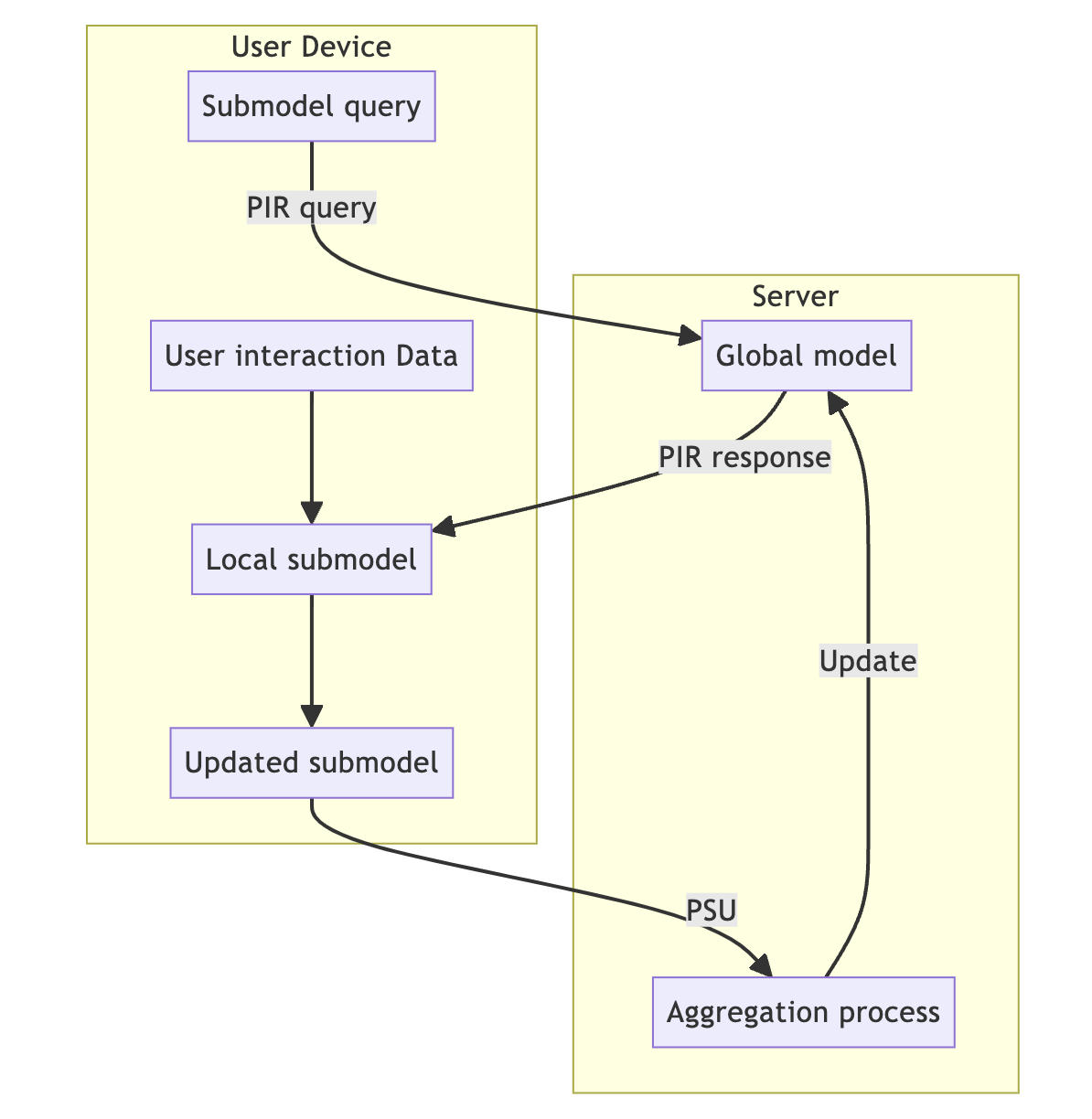
Data flow & Process
Step 1. Local model training
- User
- user interact with the DevconPassport (submits user profile, like a speaker, rate a talk)
- DevconPassport (internal)
- maintain fetched global model for inference
- retrieve a certain submodel according to the interaction (rating, likes, etc) from the central server using Private Information Retrieval (PIR) protocol
- run submodel learning process concurrently and periodically (not a real-time for each interaction)
Step 2. Model update
- DevconPassport
- send updated submodel
- Server
- collect updated submodels by a certain period
Step 3. Aggregation
- Server
- run aggregation securely using Private Set Union (PSU) protocol
Step 4. Global model distribution
- User
- Fetch the updated global model (on-device or online, it is not discussed in this proposal but it depends on which model will be used)
Step 5. Inference
- User
- if on-device model is used, it doesn’t send any query to the server
- or send a query to the global model, and get a response from the server
(Step 6. Summary on the website)
- Website
- Show the utility of this training’s from the global perspective (need to think about this idea more)
Data flow diagram
Below is a simple visual representation of the data flow of this system:
Things to clarify:
- How is this current recommender feature built? It seems like some kind of LLM chat bot has been integrated, but does this recommender take user profile (such as job titles/tracks/tag they submit when they make an account) into account?

-
Does DevconPassport team own a server and store user profile data there? how is it used?
-
Would it be possible to implement this for Devconnect as well?